publications
2026
-
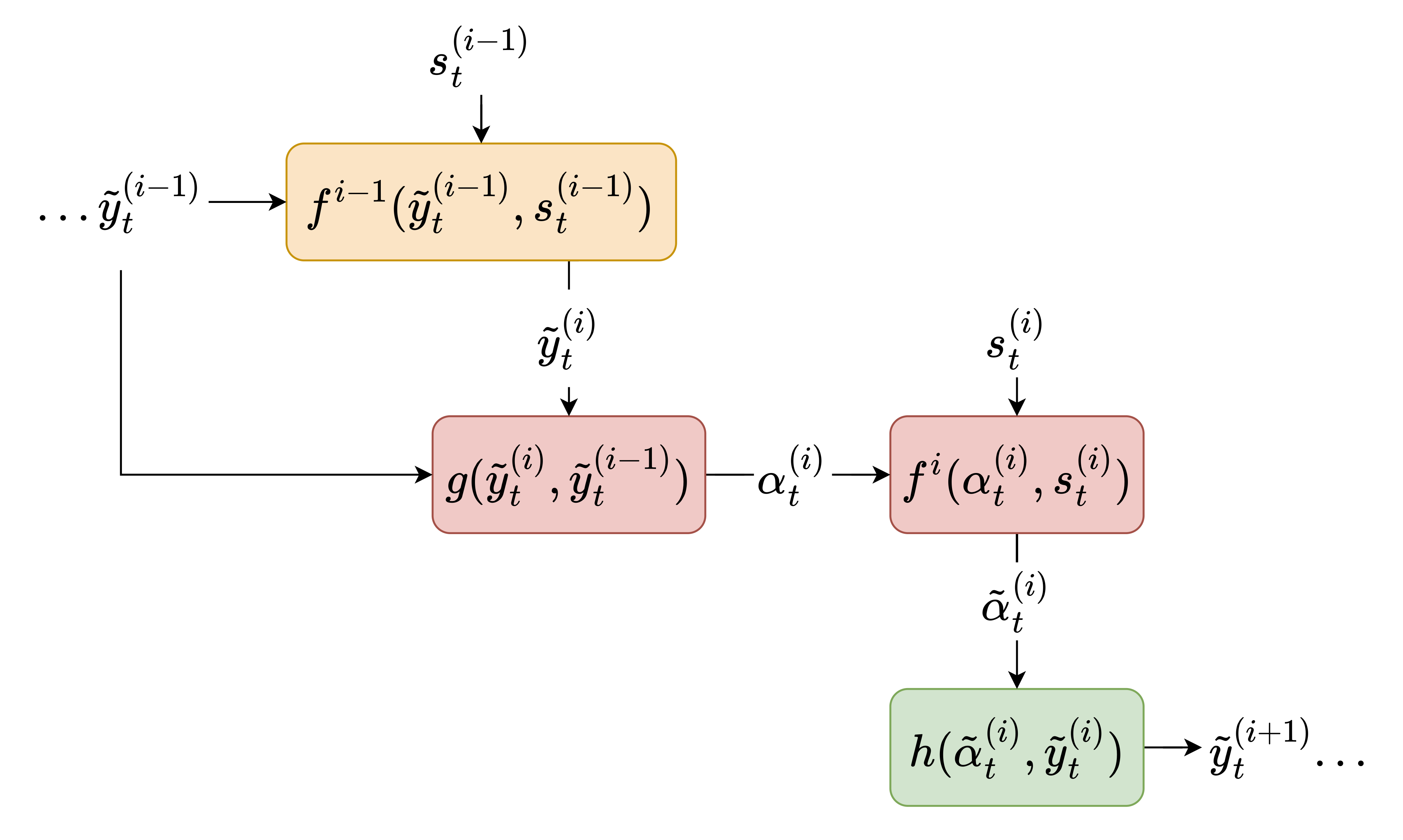 Hierarchical ensemble-based feature selection for time series predictionHuseyin Karaca, Aysin Tumay, Ali Taha Koc, and Suleyman Serdar KozatDigital Signal Processing, 2026
Hierarchical ensemble-based feature selection for time series predictionHuseyin Karaca, Aysin Tumay, Ali Taha Koc, and Suleyman Serdar KozatDigital Signal Processing, 2026We introduce a hierarchical ensemble-based feature selection (HEFS) method specifically designed for high-dimensional, non-stationary time series prediction tasks. Traditional methods typically select a single dominant subset of features, potentially neglecting valuable information from non-selected subsets. In contrast, our approach employs a multi-layer hierarchical structure, where dominant features are initially used to train the first layer, and non-dominant features are sequentially processed in subsequent layers. A novel cost-optimization block bridges each layer, recalibrating the predictions of the previous layer by directly minimizing the final loss. Thus, effectively capturing interactions across feature groups in different layers and overcoming some of the limitations of classical gradient boosting-based ensembles. Extensive experiments on synthetic and real-world datasets demonstrate that our method significantly outperforms classical approaches in predictive accuracy and robustness against overfitting. To promote transparency and reproducibility, we publicly share our implementation code.
2025
-
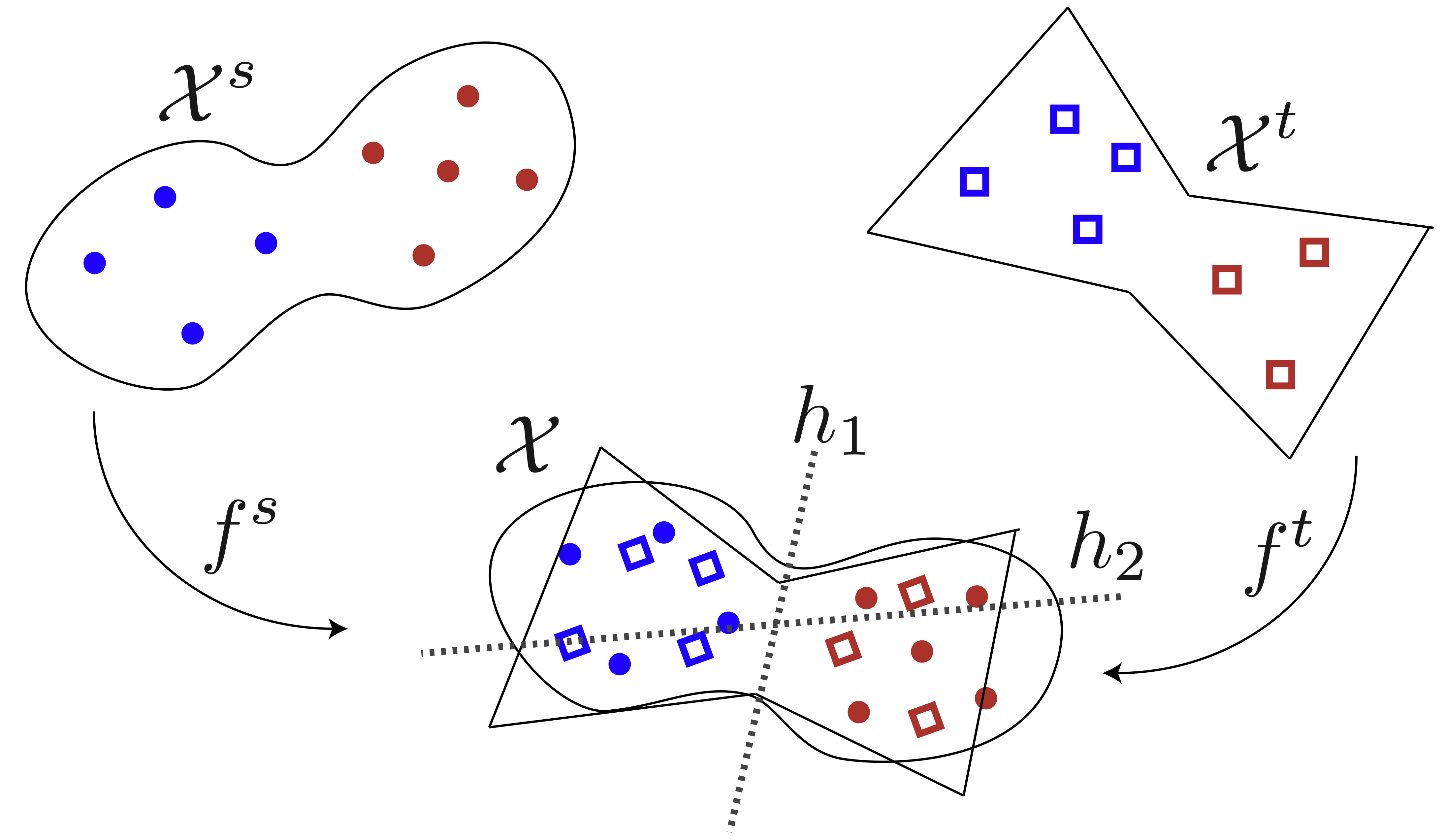 A Unified Analysis of Generalization and Sample Complexity for Semi-Supervised Domain AdaptationElif Vural and Huseyin Karaca2025
A Unified Analysis of Generalization and Sample Complexity for Semi-Supervised Domain AdaptationElif Vural and Huseyin Karaca2025Domain adaptation seeks to leverage the abundant label information in a source domain to improve classification performance in a target domain with limited labels. While the field has seen extensive methodological development, its theoretical foundations remain relatively underexplored. Most existing theoretical analyses focus on simplified settings where the source and target domains share the same input space and relate target-domain performance to measures of domain discrepancy. Although insightful, these analyses may not fully capture the behavior of modern approaches that align domains into a shared space via feature transformations. In this paper, we present a comprehensive theoretical study of domain adaptation algorithms based on domain alignment. We consider the joint learning of domain-aligning feature transformations and a shared classifier in a semi-supervised setting. We first derive generalization bounds in a broad setting, in terms of covering numbers of the relevant function classes. We then extend our analysis to characterize the sample complexity of domain-adaptive neural networks employing maximum mean discrepancy (MMD) or adversarial objectives. Our results rely on a rigorous analysis of the covering numbers of these architectures. We show that, for both MMD-based and adversarial models, the sample complexity admits an upper bound that scales quadratically with network depth and width. Furthermore, our analysis suggests that in semi-supervised settings, robustness to limited labeled target data can be achieved by scaling the target loss proportionally to the square root of the number of labeled target samples. Experimental evaluation in both shallow and deep settings lends support to our theoretical findings.
-
 Soft Gradient Boosting with Learnable Feature Transforms for Sequential RegressionHuseyin Karaca and Suleyman Serdar KozatIEEE Signal Processing Letters, 2025
Soft Gradient Boosting with Learnable Feature Transforms for Sequential RegressionHuseyin Karaca and Suleyman Serdar KozatIEEE Signal Processing Letters, 2025We propose a soft gradient boosting framework for sequential regression that embeds a learnable linear feature transform within the boosting procedure. At each boosting iteration, we train a soft decision tree and learn a linear input feature transform \bfQ together. This approach is particularly advantageous in high-dimensional, data-scarce scenarios, as it discovers the most relevant input representations while boosting. We demonstrate, using both synthetic and real-world datasets, that our method effectively and efficiently increases the performance by an end-to-end optimization of feature selection/transform and boosting while avoiding overfitting. We also extend our algorithm to differentiable non-linear transforms if overfitting is not a problem. To support reproducibility and future work, we share our code publicly.
-
 Diffractive processors enable all-optical image denoisingIşıl, Hanlong Chen, Tianyi Gan, F. Onuralp Ardic, Koray Mentesoglu, Jagrit Digani, Huseyin Karaca, Jingxi Li, Deniz Mengu, Mona Jarrahi, Kaan Akşit, and Aydogan OzcanIn AI and Optical Data Sciences VI, 2025
Diffractive processors enable all-optical image denoisingIşıl, Hanlong Chen, Tianyi Gan, F. Onuralp Ardic, Koray Mentesoglu, Jagrit Digani, Huseyin Karaca, Jingxi Li, Deniz Mengu, Mona Jarrahi, Kaan Akşit, and Aydogan OzcanIn AI and Optical Data Sciences VI, 2025We report an all-optical image-denoising approach utilizing spatially-engineered diffractive layers, forming a diffractive optical network. Diffractive features on these transmissive layers are optimized using deep learning for all-optical image denoising. Once trained, these optimized layers are fabricated to form a passive optical network to scatter optical modes associated with undesired noise features while preserving image details with minimal deterioration, thereby denoising the input images at the speed of light propagation through a thin diffractive volume. The effectiveness of this diffractive image denoising system was demonstrated for the elimination of salt and pepper noise and Monte Carlo rendering artifacts. This all-optical denoising method was further validated through a proof-of-concept experiment using a 3D-printed diffractive network operating at the THz spectrum. These diffractive image denoisers operate rapidly to all-optically perform noise filtering without requiring digital computation and can achieve high diffraction efficiencies of up to 40% without compromising their denoising performance.
2024
-
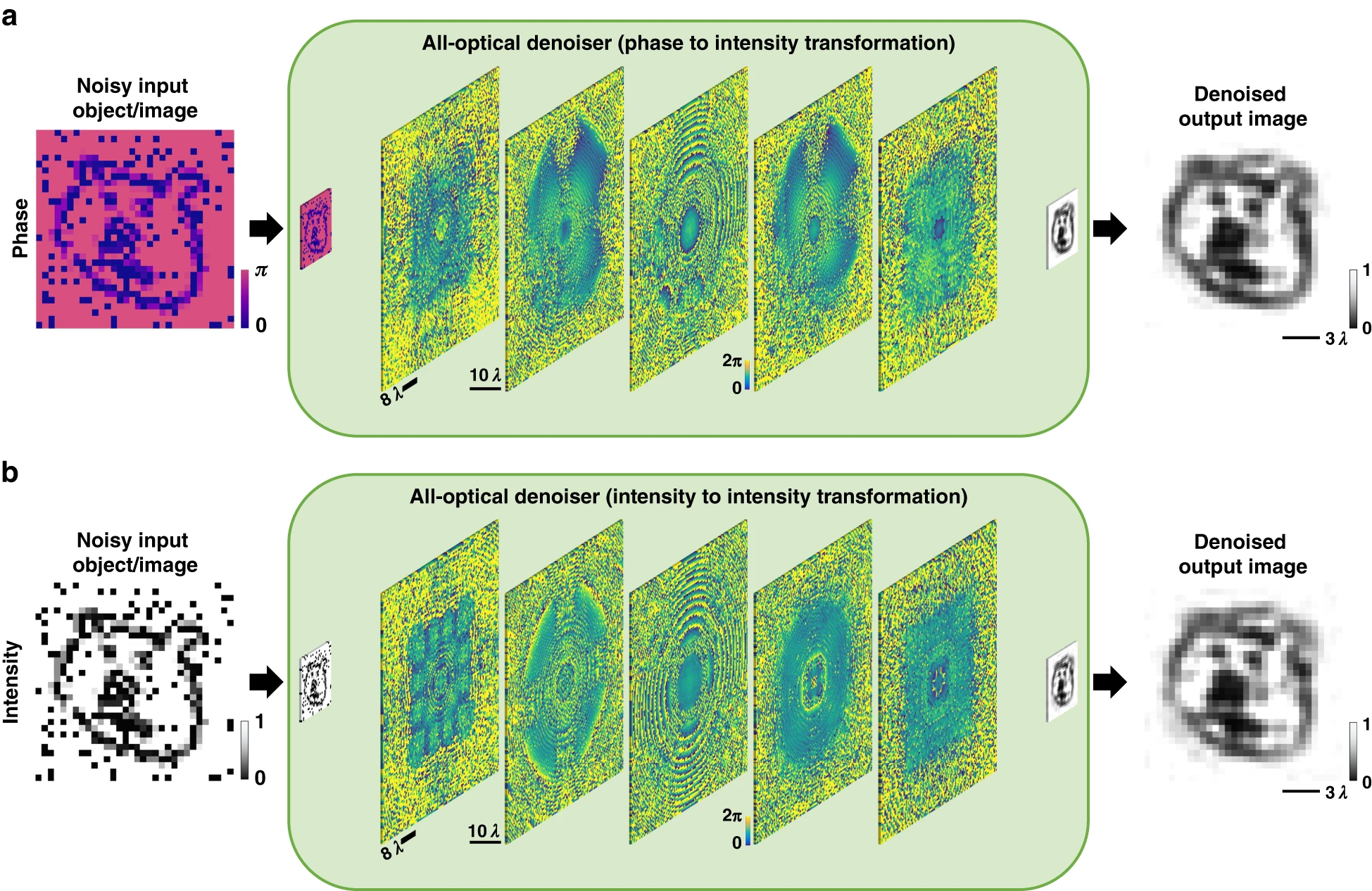 All-optical image denoising using a diffractive visual processorÇağatay Işıl, Tianyi Gan, Fazil Onuralp Ardic, Koray Mentesoglu, Jagrit Digani, Huseyin Karaca, Hanlong Chen, Jingxi Li, Deniz Mengu, Mona Jarrahi, Kaan Akşit, and Aydogan OzcanLight: Science & Applications, Feb 2024
All-optical image denoising using a diffractive visual processorÇağatay Işıl, Tianyi Gan, Fazil Onuralp Ardic, Koray Mentesoglu, Jagrit Digani, Huseyin Karaca, Hanlong Chen, Jingxi Li, Deniz Mengu, Mona Jarrahi, Kaan Akşit, and Aydogan OzcanLight: Science & Applications, Feb 2024Image denoising, one of the essential inverse problems, targets to remove noise/artifacts from input images. In general, digital image denoising algorithms, executed on computers, present latency due to several iterations implemented in, e.g., graphics processing units (GPUs). While deep learning-enabled methods can operate non-iteratively, they also introduce latency and impose a significant computational burden, leading to increased power consumption. Here, we introduce an analog diffractive image denoiser to all-optically and non-iteratively clean various forms of noise and artifacts from input images – implemented at the speed of light propagation within a thin diffractive visual processor that axially spans \textless250 × λ, where λ is the wavelength of light. This all-optical image denoiser comprises passive transmissive layers optimized using deep learning to physically scatter the optical modes that represent various noise features, causing them to miss the output image Field-of-View (FoV) while retaining the object features of interest. Our results show that these diffractive denoisers can efficiently remove salt and pepper noise and image rendering-related spatial artifacts from input phase or intensity images while achieving an output power efficiency of ~30–40%. We experimentally demonstrated the effectiveness of this analog denoiser architecture using a 3D-printed diffractive visual processor operating at the terahertz spectrum. Owing to their speed, power-efficiency, and minimal computational overhead, all-optical diffractive denoisers can be transformative for various image display and projection systems, including, e.g., holographic displays.
2023
-
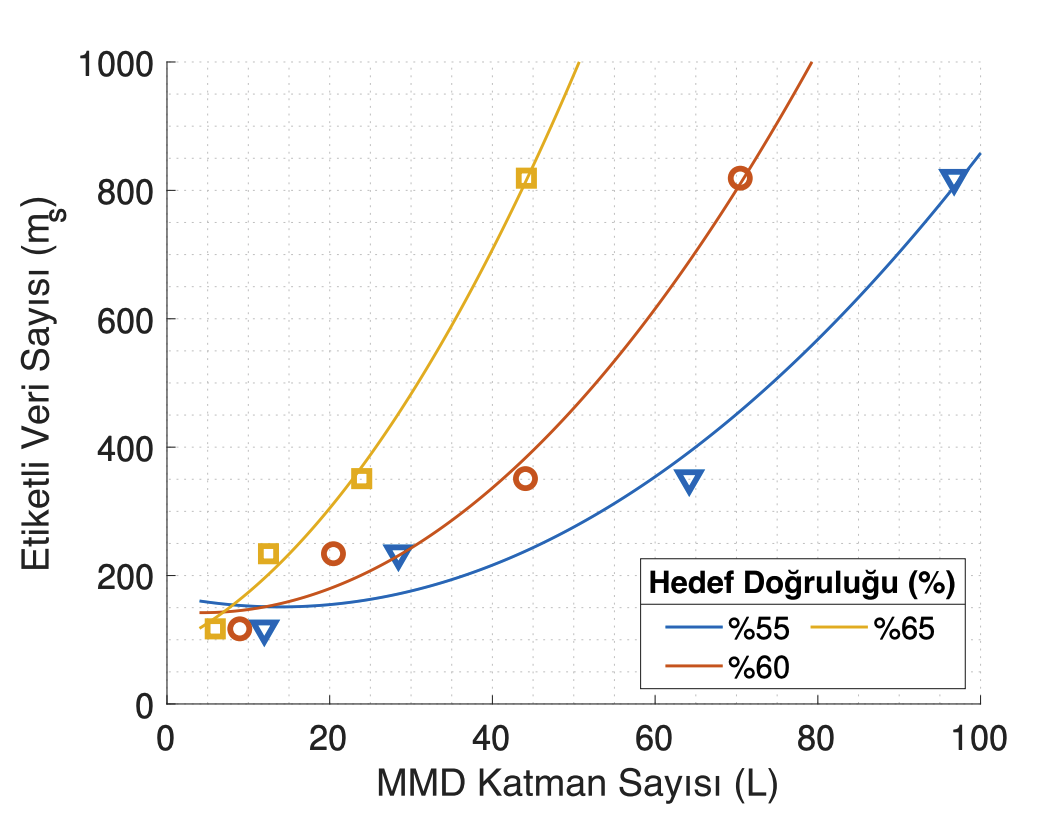 An Experimental Study of the Sample Complexity of Domain AdaptationHüseyin Karaca, Özlem Akgül, Ömer Faruk Arslan, Atilla Can Aydemir, Firdevs Su Aydin, Enes Ata Ünsal, and Elif VuralIn 2023 31st Signal Processing and Communications Applications Conference (SIU), Jul 2023
An Experimental Study of the Sample Complexity of Domain AdaptationHüseyin Karaca, Özlem Akgül, Ömer Faruk Arslan, Atilla Can Aydemir, Firdevs Su Aydin, Enes Ata Ünsal, and Elif VuralIn 2023 31st Signal Processing and Communications Applications Conference (SIU), Jul 2023In this study, we experimentally investigate the sample complexity of semi supervised domain adaptation with deep neural networks. Sweeping the hyper-parameters of domain adaptation neural networks relying on the MMD distance measure and the number of training samples in a controlled manner, we study the test accuracy of the target samples. Both labeled and unlabeled samples from the source and the target domains are used as inputs to the neural network in the experiments. Our experimental findings suggest that the minimum number of samples required for guaranteeing a fixed experimental target accuracy level increases quadratically with both the number and the dimension of the MMD layers in the network used for aligning the source and the target domains. We observe that this relationship is in harmony with some well-known theoretical bounds in the classical deep learning literature. Meanwhile, we also investigate the optimal weighting strategy between the classification loss functions of the source and the target samples, concluding that increasing the weight of the target loss improves the performance as the number of target samples increases.